
Many students enrolled in Database Design and Implementation college coursework have for many years struggled completing various Database Design and Implementation assignments. The reason for this has either been due to lack of enough skills to solve cloud computing coursework problems. In other cases, it happens when students have many coursework requirements they need to work on hence lacking sufficient time to write a good cloud computing essays. Whichever the case, students can utilize the services of All Homework Assignments to get the best Database Design and Implementation assignment help. The website is authentic and has been in operation for more than a decade.
Our Database Design And Implementation Experts have prepared sample assignment solution to demonstrate the quality of our work. All the solutions have been prepared by following a simplistic approach and include step by step explanations. These solutions reflect the in-depth expertise and experience of our online Database Design And Implementation assignment experts.
Scenario
In this scenario, you have recently been hired as a Data Engineer by a New York based coffee shop chain that is looking to expand nationally by opening a number of franchise locations. As part of their expansion process, they want to streamline operations and revamp their data infrastructure.
Your job is to design their relational database systems for improved operational efficiencies and to make it easier for their executives to make data driven decisions.
Currently their data resides in several different systems: accounting software, suppliers’ databases, point of sales (POS) systems, and even spreadsheets. You will review the data in all of these systems and design a central database to house all of the data. You will then create the database objects and load them with source data. Finally, you will create subsets of data that your business partners require, export them, and then load them into staging databases that use different RDBMS.
Software used in this project
In this project, you will use PostgreSQL Database, IBM Db2 Database, and MySQL. These are all relational database management systems (RDBMS) designed to efficiently store, manipulate, and retrieve the data.
Data used in this project
In this project, you will be working with a subset of data from the Coffee shop sample data.
You will use a modified version of the data for the project, so to succeed in the project, download the linked files when prompted in the instructions. You do not need to use any data from the original source.
In your scenario, you will be working with data from the following sources:
Staff information held in a spreadsheet at HQ
Sales outlet information held in a spreadsheet at HQ
Sales data output as a CSV file from the POS system in the sales outlets
Customer data output as a CSV file from a bespoke customer relationship management system
Product information maintained in a spreadsheet exported from your supplier’s database
Objectives
After completing this lab, you will be able to:
Identify entities.
Identity attributes.
Create an entity relationship diagram (ERD) using the pgAdmin ERD Tool.
Normalize tables.
Define keys and relationships.
Create database objects by generating and running the SQL script from the ERD Tool.
Create a view and export the data.
Create a materialized view and export the data.
Import data into a Db2 database.
Import data into a MySQL database.
Task 1: Identify entities
The first step when designing a new database is to review any existing data and identify the entities for your new system.
1. The following image shows sample data from each of the data sources that you will be working with to design your new central database. Review the image and identify the entities you plan to create.
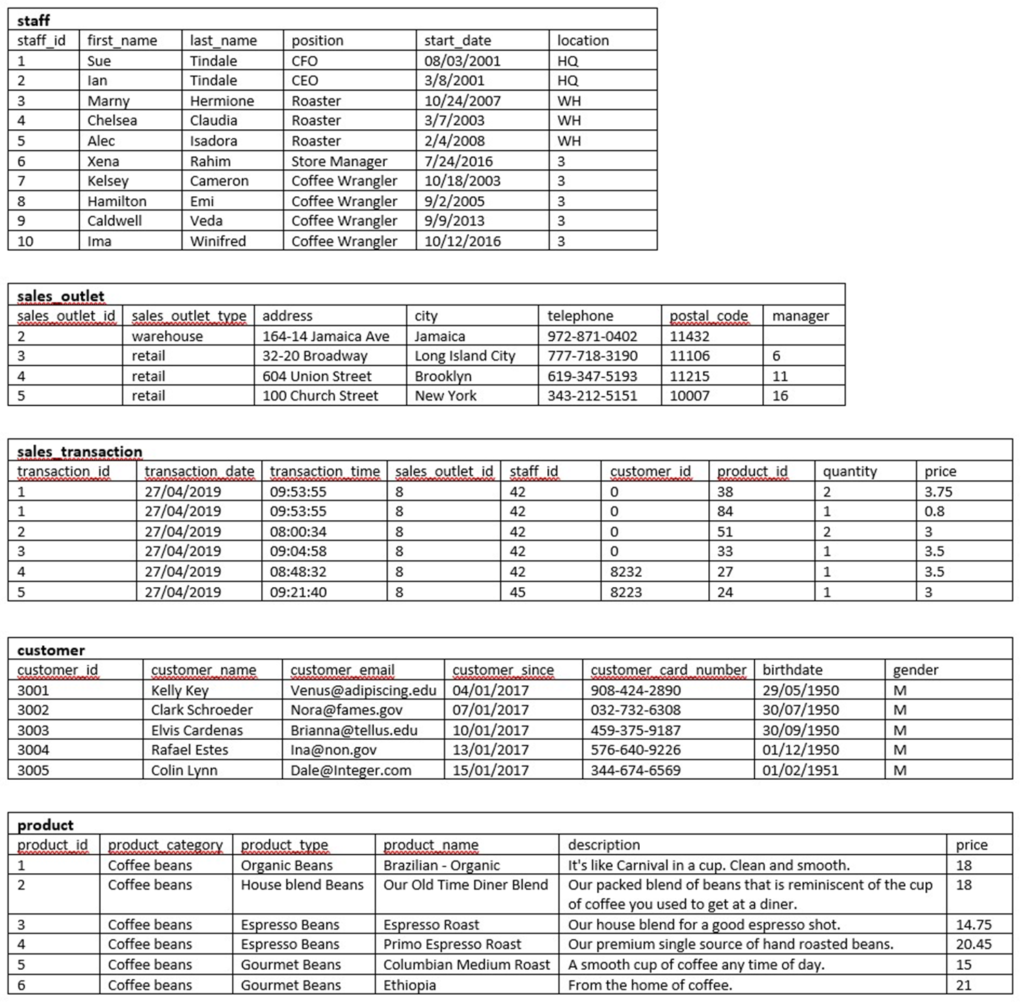
Task 2: Identify attributes
In this task, you will identify the attributes for one of the entities that you plan to create.
- Using the information from the sample data in the image from Task 1, identify the attributes for the entity that will store the sales transaction data.
- Make a list of the sales transaction attributes that you identified.
Task 3: Create an ERD
Now that you have defined some of your attributes and entities, you can determine the tables and columns for them and create an ERD.
- Open a new terminal from the side-by-side Cloud IDE.
- Use the start_postgres command to start a PostgreSQL service session in the Cloud IDE.
- Use the pgAdmin weblink to open pgAdmin in a new tab in your browser.
- Create a new database named COFFEE, view the schemas in the new COFFEE database, and then start a new ERD project.
- Add a table to the ERD for the sale transactions entity using the information in the following table. Consider what naming convention to use so that your colleagues will be able to understand your data and to ensure that the names are valid in other RDBMS. And use the sample data shown in the image in Task 1 to determine appropriate data types for each column.

- Take a screenshot of your ERD and save it as Task3A.png or Task3A.jpg.
- Add a table to the ERD for the product entity using the information in the following table. Consider what naming convention to use so that your colleagues will be able to understand your data and to ensure that the names are valid in other RDBMS. And use the sample data shown in the image in Task 1 to determine appropriate data types for each column.
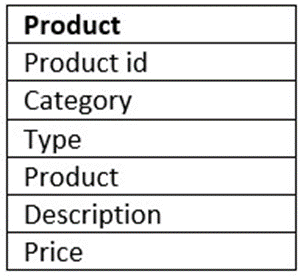
- Take a screenshot of your ERD and save it as Task3B.png or Task3B.jpg.
Task 4: Normalize tables
When reviewing your ERD you notice that it does not conform to second normal form. In this task, you will normalize some of the tables within the database.
- Review the data in the sales transaction table. Note that the transaction id column does not contain unique values because some transactions include multiple products.
- Determine which columns should be stored in a separate table to remove the repeating rows and to put this table into second normal form.
3 Add a new table named sales_detail to the ERD, define the columns in the new table, and delete the moved columns from the sales transaction table, leaving a matching column in each of two tables to later create a relationship between them.
- Take a screenshot of your ERD and save it as Task4A.png or Task4A.jpg.
- Review the data in the product table. Note that the product category and product type columns contain redundant data.
- Determine which columns should be stored in a separate table to reduce redundant data and to put this table into second normal form.
- Add a new table named product_type to the ERD, define the columns in the new table, and delete the moved columns from the product table, , leaving a matching column in each of two tables to later create a relationship between them.
- Take a screenshot of your ERD and save it as Task4B.png or Task4B.jpg.
Task 5: Define keys and relationships
After normalizing your tables, you can define their primary keys and define relationships between the tables in your ERD.
- Identify an appropriate column in each table to be a primary key and create the primary keys in the tables in your ERD.
- Take a screenshot of your ERD and save it as Task5A.png or Task5A.jpg.
- Identify the relationships between the following pairs of tables and then create the relationships in your ERD
- Take a screenshot of your ERD and save it as Task5B.png or Task5B.jpg.
Task 6: Create database objects by generating and running the SQL script from the ERD Tool
Now that your design is complete, you will generate an SQL script from your ERD which you could use to create your database schema. For the purposes of this project, you will then use a provided SQL script to ensure that you will be able to successfully load the sample data into the schema. Finally, you will load the existing data from the various data sources into your new database schema.
- Use the Generate SQL functionality in the ERD Tool to create an SQL script from your ERD.
- Download the GeneratedScript.sql file below to your local computer storage.
- In pgAdmin, open the Query Tool, upload and open the GeneratedScript.sql file from your local computer storage, and then execute the script to create the tables defined in the ERD. Verify that the tables now exist in the public schema of the COFFEE database.
- Take a screenshot of the tables shown in the tree-view pane on the left-hand side of the page and save it as Task6A.png or Task6A.jpg.
- Download the CoffeeData.sql file below to your local computer storage.
- In pgAdmin, open another instance of the Query Tool, upload and open the CoffeeData.sql file from your local computer storage, and then execute the script to populate the tables you just created.
- In pgAdmin, view the first 100 rows of the sales_detail table.
- Take a screenshot of the Data Output pane and save it as Task6B.png or Task6B.jpg.
Task 7: Create a view and export the data
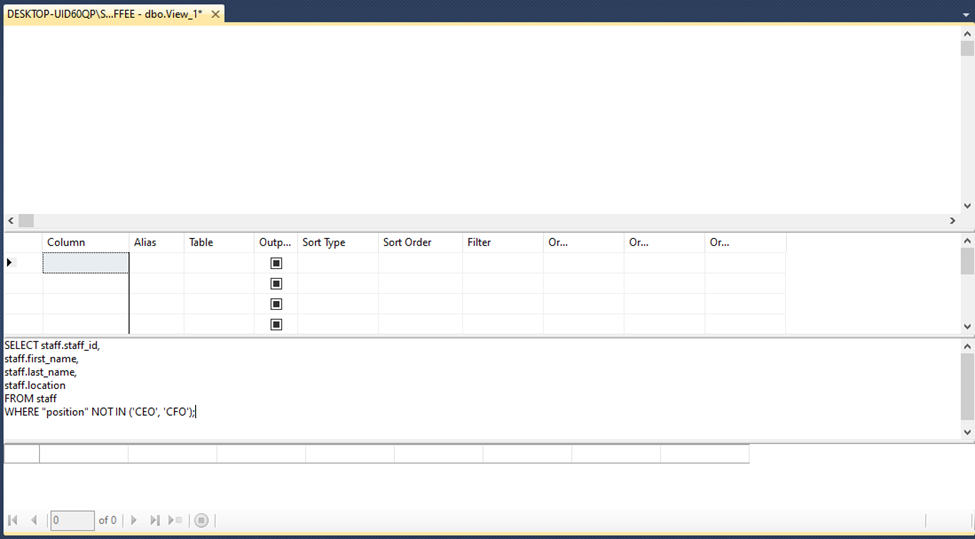
The external payroll company have requested a list of employees and the locations at which they work. This should not include the CEO or CFO who own the company. In this task, you will create a view in your PostgreSQL database that returns this information and export the results to a CSV file.
1 In your COFFEE database, create a new view named staff_locations_view using the following SQL:
| SELECT staff.staff_id, staff.first_name, staff.last_name, staff.location FROM staff WHERE “position” NOT IN (‘CEO’, ‘CFO’); |
- View all the rows returned from the view.
- Save the results of the query to a file named staff_locations_view.csv on your local computer storage.
- Take a screenshot of the view shown in the tree-view pane on the left-hand side of the page alongside the results in the Data Output pane, and save it as Task7.png or Task7.jpg.
Task 8: Create a materialized view and export the data
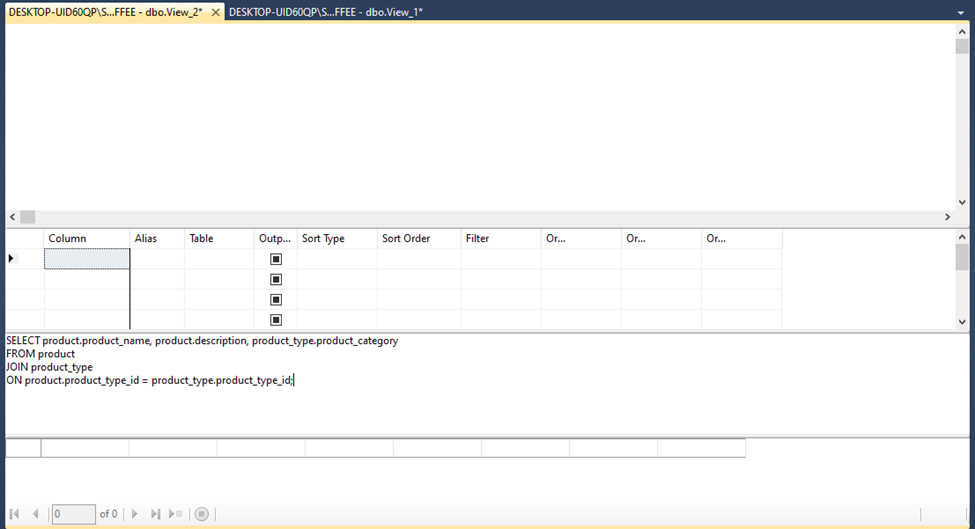
A marketing consultant requires access to your product data in their MySQL database for a marketing campaign. You will create a materialized view in your PostgreSQL database that returns this information and export the results to a CSV file.
- In your COFFEE database, create a new materialized view named product_info_m-view using the following SQL:
SELECT product.product_name, product.description, product_type.product_category
FROM product
JOIN product_type
ON product.product_type_id = product_type.product_type_id;
- Refresh the materialized view with data.
- View all the rows returned from the view.
- Save the results of the query to a file named product_info_m-view.csv on your local computer storage.
- Take a screenshot of the view shown in the tree-view pane on the left-hand side of the page alongside the results in the Data Output pane, and save it as Task8.png or Task8.jpg.
Task 9: Import data into a Db2 database
The external payroll company have asked you to upload the staff location information to their Db2 database.
- In a new browser tab, log in using your credentials, and then open a console for your Db2 on Cloud instance that you created earlier in this course.
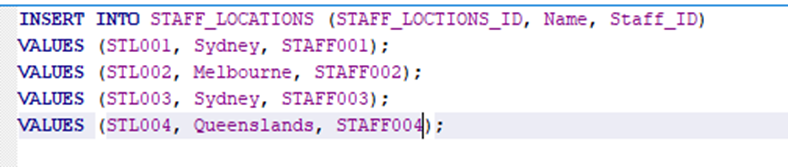
- Use the Load Data feature to load a new table named STAFF_LOCATIONS with the staff location information saved in the staff_locations_view.csv file that you exported from the view you created in Task 7.
- Explore the new table and then view the data in it.
- Take a screenshot of the contents of the new table and save it as Task9.png or Task9.jpg.
Task 10: Import data into a MySQL database
The marketing consultant has asked you to upload the product information to their MySQL database.
- In the terminal from the side-by-side Cloud IDE, use the start_mysql command to start a My SQL service session in the Cloud IDE.
- Use the browser weblink to open phpMyAdmin in a new tab in your browser.
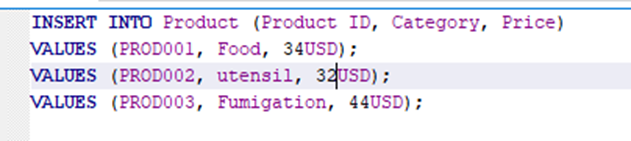
- In phpMyAdmin, create a new database named coffee_shop_products, and then import the product information saved in the product_info_m-view.csv file from your materialized view into a new table in the coffee_shop_products database.
- Browse the contents of the new table.
5 Take a screenshot of the contents of the new table and save it as Task10.png or Task10.jpg.
Author(s)
Lin Joyner
Other Contributor(s)
Changelog
Date Version Changed by Change Description
2021-04-01 1.0 Lin Joyner Created initial version
SOLUTION:
Task 1: Entity Identification
The following are the entities that have been identified from the database system of the Coffee Shop:
- Staff
- Sales_Outlet
- Sales_transaction
- Customer
- Product
Task 2: Attributes Identification
- Using the information from the sample data in the image from Task 1, identify the attributes for the entity that will store the sales transaction data
The following are the attributes of the entity Sales_transaction:
- Transaction_ID
- Transaction_Date
- Transaction_Time
- Sales_Outlet_ID
- Staff_ID
- Customer_ID
- Product_ID
- Quantity
- Price
Task 3: ERD Creation
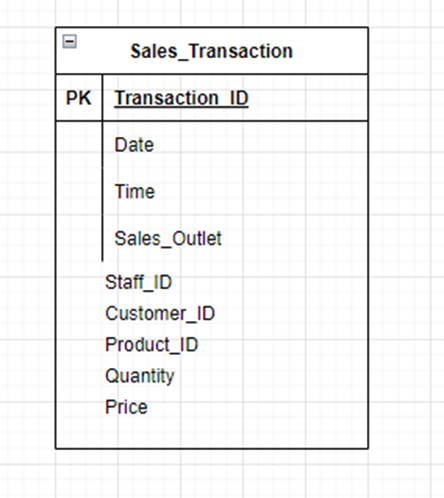
The figure below shows an ERD image of the Sales Transaction entity
The diagram below shows the resulting ERD image after the addition of the Product entity
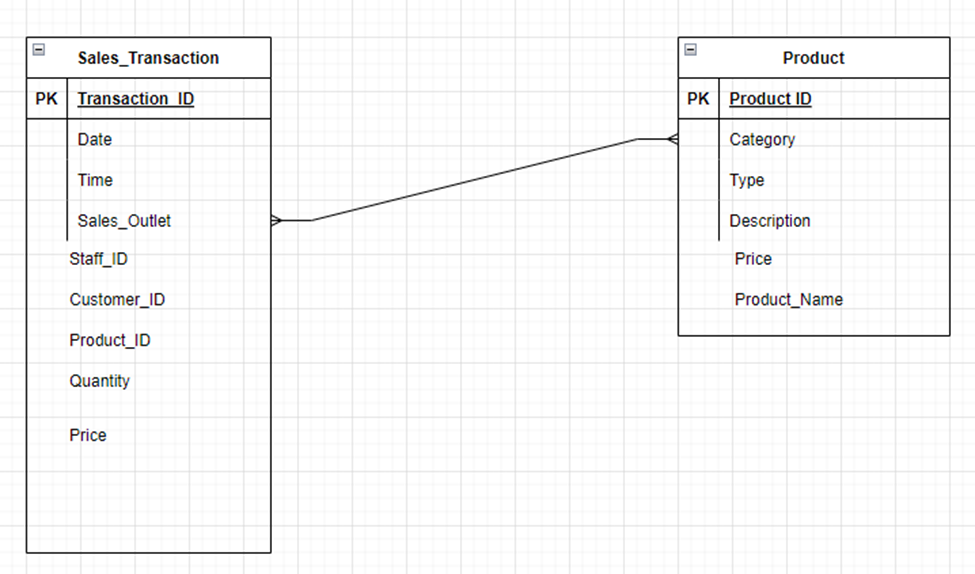
The following image shows the ERD image when all the other entities are added:
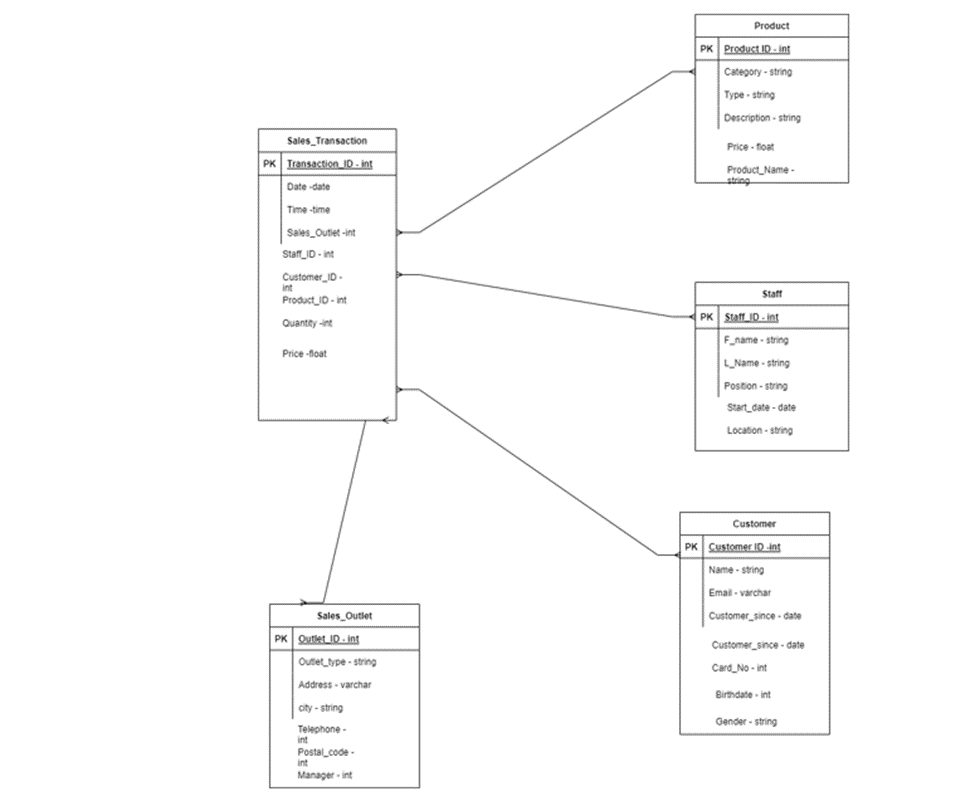
Task 4: Table Normalization
- Review the data in the sales transaction table. Note that the transaction id column does not contain unique values because some transactions include multiple products.
- Determine which columns should be stored in a separate table to remove the repeating rows and to put this table into second normal form.
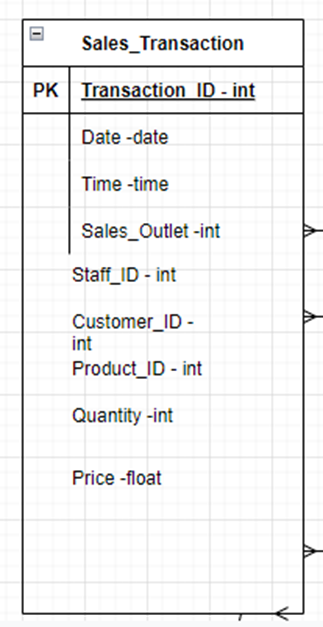
The following are the columns/attributes that should be stored in a separate table; staff ID, Customer ID, Product ID, Quantity, and Price.
After creating of the new table, Sales_details, the resulting table will be as follows:

The above table is in its 1NF. Hence, it can be further normalized into its 2NF. Rules for 2NF states that:
- A table should be in its 1NF.
- Functional dependencies are removed.
The attribute time functionally depends on the other attribute; data. Thus in this case the time attribute is removed.
- Add a new table named sales_detail to the ERD, define the columns in the new table, and delete the moved columns from the sales transaction table, leaving a matching column in each of two tables to later create a relationship between them.
- Take a screenshot of your ERD and save it as Task4A.png or Task4A.jpg.
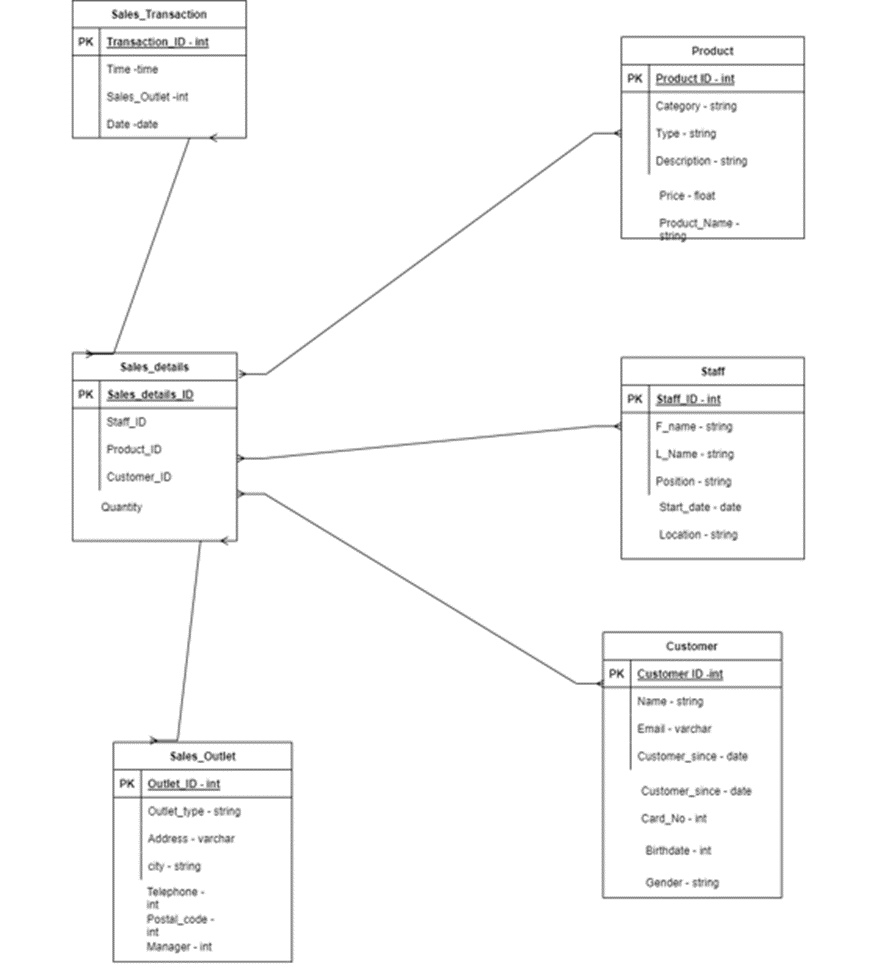
5. Review the data in the product table. Note that the product category and product type columns contain redundant data.
6. Determine which columns should be stored in a separate table to reduce redundant data and to put this table into second normal form.
It is product type entity that should be stored in a different table. Thus, the table product will have the following entities; Product ID, Category, Description, and Price Product Name. To normalize the table into its 2NF equivalent, functional dependency is removed. In this case, the attribute description functionally depends on the product name. Thus, the attribute description is removed in this case.
7. Add a new table named product_type to the ERD, define the columns in the new table, and delete the moved columns from the product table, leaving a matching column in each of two tables to later create a relationship between them.
8. Take a screenshot of your ERD and save it as Task4B.png or Task4B.jpg.
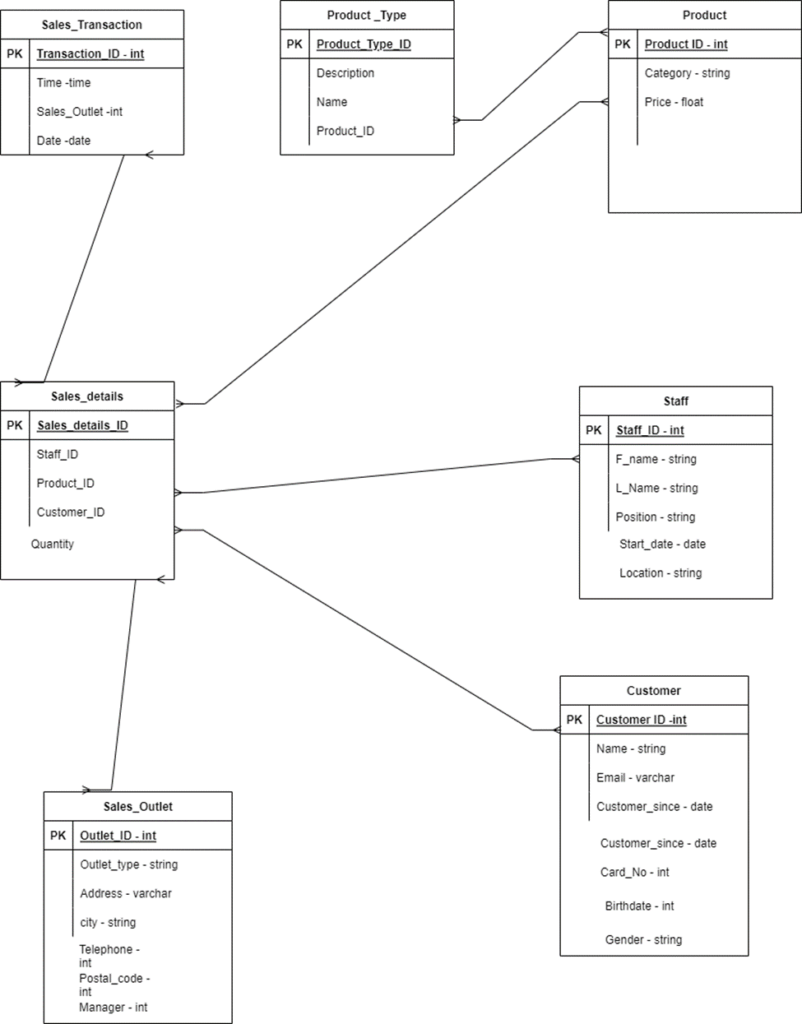
Task 5: Defining Keys and Relationships
| Table | Primary Key |
| Sales_Transaction | Sales_Transaction_ |
| Product_ Type | Product-Type_ID |
| Product | Product_ID |
| Sales_details | Sales_details_ID |
| Staff | Staff_ID |
| Sales_Outlet | Sales_Outlet_ID |
| Customer | Customer_ID |
The following image shows an ERD image where all the primary keys of the various tables have been specified:
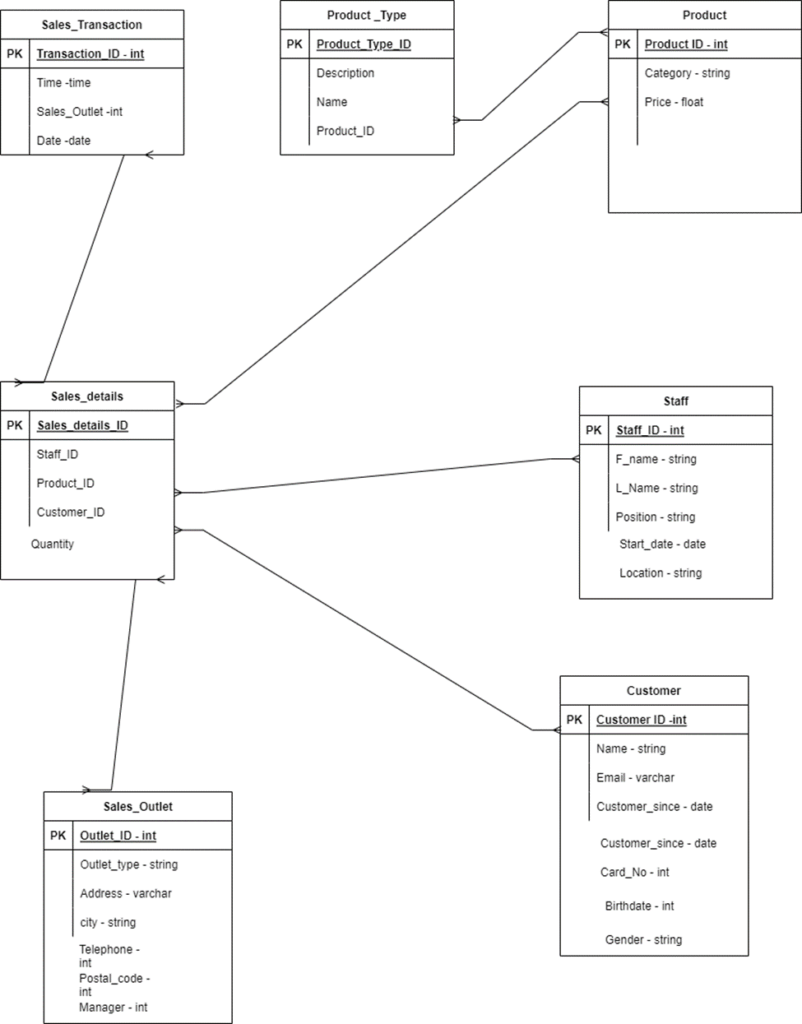
The following are the cardinalities that exist between the related entities:
- Sales_transaction to Sales_details – many-to-many.
- Product-Type to Product – One-to-one.
- Sales_details to Product – many-to-many
- Sales_details to staff – many-to-many.
- Sales_details to sales-outlets – many-to-many.
- Sales_details to customer – many-to-many.
Task 6: Create database objects by generating and running the SQL script from the ERD Tool
1. Use the Generate SQL functionality in the ERD Tool to create an SQL script from your ERD. 2. Download the GeneratedScript.sql file below to your local computer storage. GeneratedScript.sql
3. In pgAdmin, open the Query Tool, upload and open the GeneratedScript.sql file from your local computer storage, and then execute the script to create the tables defined in the ERD. Verify that the tables now exist in the public schema of the COFFEE database.
4. Take a screenshot of the tables shown in the tree-view pane on the left-hand side of the page and save it as Task6A.png or Task6A.jpg. 5. Download the CoffeeData.sql file below to your local computer storage.
5. Download the CoffeeData.sql file below to your local computer storage. CoffeeData.sql
6. In pgAdmin, open another instance of the Query Tool, upload and open the CoffeeData.sql file from your local computer storage, and then execute the script to populate the tables you just created.
7. In pgAdmin, view the first 100 rows of the sales_detail table. 8. Take a screenshot of the Data Output pane and save it as Task6B.png or Task6B.jpg.
Task 7: Create a view and export the data
- In your COFFEE database, create a new view named staff_locations_view using the following SQL:
SELECT staff.staff_id, staff.first_name, staff.last_name, staff.location FROM staff WHERE “position” NOT IN (‘CEO’, ‘CFO’);
2. View all the rows returned from the view.
3. Save the results of the query to a file named staff_locations_view.csv on your local computer storage. 4. Take a screenshot of the view shown in the tree-view pane on the left-hand side of the page alongside the results in the Data Output pane, and save it as Task7.png or Task7.jpg.
Task 8: Create a materialized view and export the data
- In your COFFEE database, create a new materialized view named product_info_m-view using the following SQL:
SELECT product.product_name, product.description, product_type.product_category FROM product JOIN product_type ON product.product_type_id = product_type.product_type_id;
- Refresh the materialized view with data. 3. View all the rows returned from the view. 4. Save the results of the query to a file named product_info_m-view.csv on your local computer storage. 5. Take a screenshot of the view shown in the tree-view pane on the left-hand side of the page alongside the results in the Data Output pane, and save it as Task8.png or Task8.jpg.
Task 9: Import data into a Db2 database
1. In a new browser tab, go to https://cloud.ibm.com/login, log in using your credentials, and then open a console for your Db2 on Cloud instance that you created earlier in this course.
2. Use the Load Data feature to load a new table named STAFF_LOCATIONS with the staff location information saved in the staff_locations_view.csv file that you exported from the view you created in Task 7.
3. Explore the new table and then view the data in it.
4. Take a screenshot of the contents of the new table and save it as Task9.png or Task9.jpg.
Task 10: Import data into a MySQL database
1. In the terminal from the side-by-side Cloud IDE, use the start_mysql command to start a My SQL service session in the Cloud IDE.
2. Use the browser weblink to open phpMyAdmin in a new tab in your browser.
3. In phpMyAdmin, create a new database named coffee_shop_products, and then import the product information saved in the product_info_m-view.csv file from your materialized view into a new table in the coffee_shop_products database.
4. Browse the contents of the new table.
5. Take a screenshot of the contents of the new table and save it as Task10.png or Task10.jpg.
Disclaimer: The samples provided by AllHomeworkAssignments.com are to be considered as model papers and are not to submitted as it is. These samples are intended to be used for research and reference purposes only.

